
2022 saw some significant advancements in artificial intelligence. My threshold for “significant” here being that the advances moved out of labs and arXiv.org preprints and into tools that many people were using and talking about. Lots of people thought text-to-image tools like DALL-E, Stable Diffusion, and Midjourney were fun. But Large Language Models (LLMs), and particularly the recent demo of ChatGPT, seem to have put the fear of God into everyone from middle school English teachers to the CEO of Google. The potential partnership between OpenAI (the makers of ChatGPT) and Microsoft may even present the first substantive challenge to Google’s search monopoly we’ve ever seen – and that’s saying something. While most of the dialog around AI and education seems to be focused on assessment, I think the implications for instructional designers are critically important, too. And, because you’ve got to play the hits, let’s look at what their impact will be on OER as well.
About Instructional Designers
I think a lot of people believe that instructional designers are the people who are really good at using the campus LMS – folks who can create new course shells for faculty, help faculty get their content uploaded into the LMS, and maybe even help with a little multimedia editing and production. Unfortunately, literally none of those things are instructional design. Instructional design is the process of leveraging what we understand about how people learn to create experiences that maximize the likelihood that the people who participate in those experiences will learn. Instructional designers need a deep understanding of both learning science research and educational technologies in order to effectively integrate them in support of learning. Uploading a syllabus PDF into Blackboard is not instructional design.
You know what else isn’t instructional design? The creation of accurate descriptions and explanations of facts, theories, and models. The raw text and images that make up the overwhelming majority of what we call textbooks. I’ve written previously about the difference between informational resources and educational resources. Wikipedia and other encyclopedias are informational resources. Reference materials and technical documentation are informational resources. The overwhelming majority of textbooks are primarily informational resources. What distinguishes an educational resource from an informational resource is that the latter shows some intentional application of knowledge about how people learn. I have previously argued that the minimum amount of effort you could invest to convert an informational resource into an educational resource was to add practice with feedback. That simple sounding task quickly explodes in complexity as you consider the research on what form that practice should take, how long it should last, when it should be scheduled, what kind of feedback should be provided, whether the feedback should come immediately or after some delay, etc.
Now, please don’t misunderstand me – there is absolutely an art and science to creating accurate, beautiful informational resources. It’s just a different art and science from the one involved in creating educational resources. All educational resources begin as informational resources, so they are critically important to the work we do as instructional designers. You might say they are a kind of intellectual infrastructure, in the way Brett Frischmann uses the term:
Intellectual infrastructure, such as basic research, ideas, general purpose technologies, and languages, creates benefits for society primarily by facilitating a wide range of downstream productive activities, including information production, innovation, and the development of products and services, as well as education, community building and interaction, democratic participation, socialization, and many other socially valuable activities. (emphasis added)
Informational resources (especially openly licensed ones) facilitate a wide range of downstream productive activities, including the creation of educational resources. Or, to use language I have used often before, informational resources are “content infrastructure” upon which instructional designers build when they create educational resources.
LLMs Will Make Creating the Content Infrastructure Significantly Easier, Faster, and Cheaper
LLMs will dramatically increase the speed of creating the informational resources that comprise the content infrastructure. Of course the drafts of these informational resources will need to be reviewed and improvements will need to be made – just as is the case with all first drafts – to insure accuracy and timeliness. But it appears that LLMs can get us 80% or so of the way to reasonable first drafts orders of magnitude faster, eliminating the majority of the expense involved in this part of the process. Here’s an example of what I’m talking about. Imagine you’re a SME who has been tasked with writing the content for an introductory economics textbook. (The following examples are from ChatGPT.)
Definitions and Examples
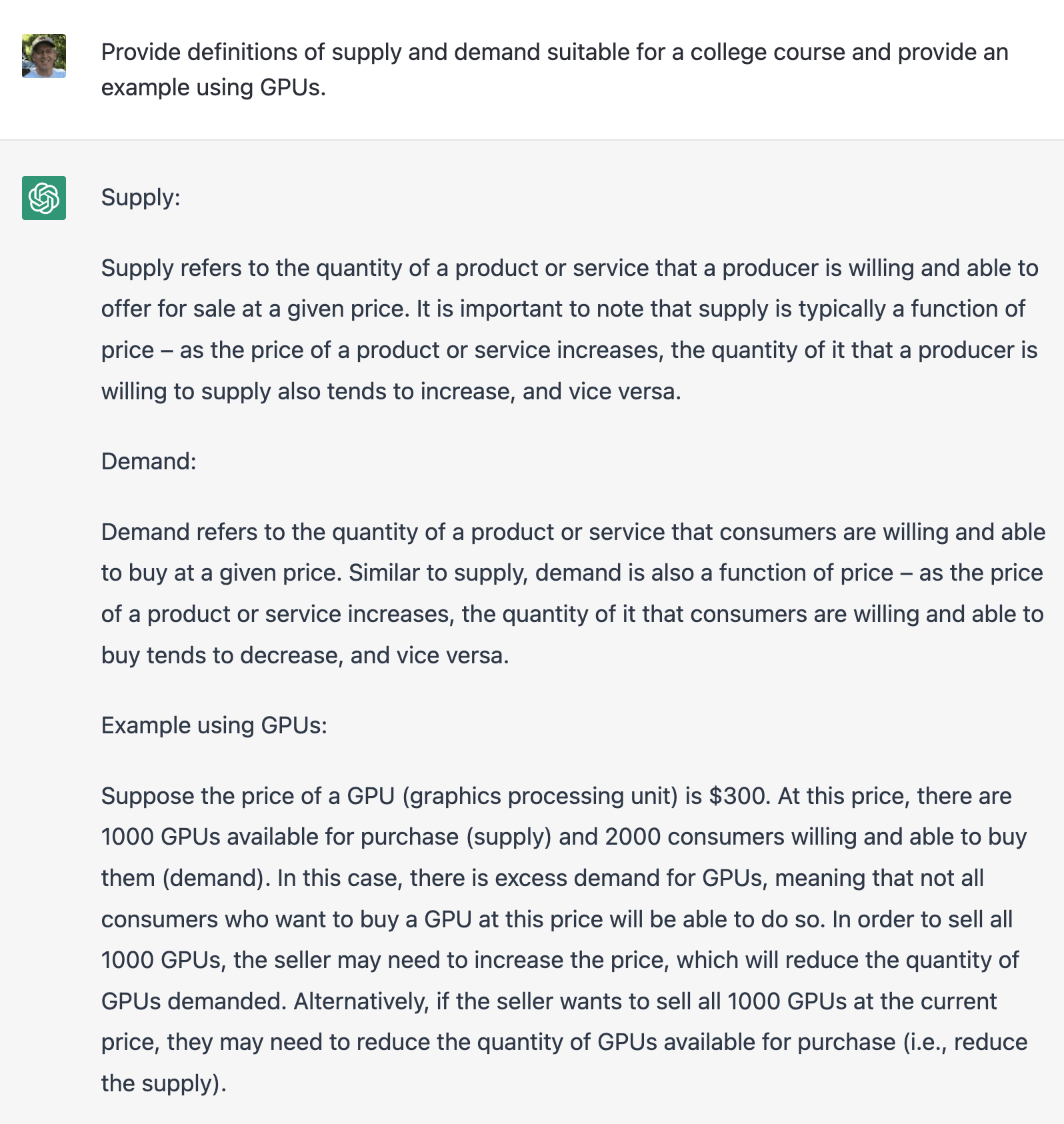
That’s not quite right, but it’s far faster to feed a prompt into ChatGPT and then edit the output to make it accurate than it would be to write that from scratch. And I think this will always be the way to think about these tools – incredibly helpful for creating first drafts for humans to then review, augment, and polish.
But LLMs won’t just help SMEs – they can also provide instructional designers with first drafts of some of the work they do. Imagine you’re an instructional designer who’s been paired with a faculty member to create a course in microeconomics. These tools might help you quickly create first drafts of:
Learning Outcomes

Discussion Prompts and Rubrics

Formative Assessment Items

Again, not exactly right, but an incredibly helpful starting point. Especially if you need to create several thousand assessment items.
As we see above, LLMs can engage at a basic level with concepts from the instructional design domain like discussion questions, rubrics, multiple choice questions, and feedback. But in the same way that a SME in a discipline needs to check a draft informational resource for accuracy of information, an instructional designer will need to check these educational resources for pedagogical and psychometric accuracy. And improvements will absolutely need to be made.
Did I Mention this Content Infrastructure Will Be Open?
In his application to register a work he created using AI software like Stable Diffusion, Steven Thaler wrote that the work “was autonomously created by a computer algorithm running on a machine” and that he was “seeking to register this computer-generated work as a work-for-hire to the owner.” In other words, he applied for copyright protection for a work he created by providing a prompt to a generative AI tool. The US Copyright Office rejected his attempt to register copyright in the work – twice. In their final response they wrote:
Copyright law only protects “the fruits of intellectual labor” that “are founded in the creative powers of the [human] mind.” COMPENDIUM (THIRD) § 306 (quoting Trade-Mark Cases, 100 U.S. 82, 94 (1879)); see also COMPENDIUM (THIRD) § 313.2 (the Office will not register works “produced by a machine or mere mechanical process” that operates “without any creative input or intervention from a human author” because, under the statute, “a work must be created by a human being”)….
While the [review] Board is not aware of a United States court that has considered whether artificial intelligence can be the author for copyright purposes, the courts have been consistent in finding that non-human expression is ineligible for copyright protection….
Courts interpreting the Copyright Act, including the Supreme Court, have uniformly limited copyright protection to creations of human authors…. For this reason, the Compendium of U.S. Copyright Office Practices — the practice manual for the Office — has long mandated human authorship for registration…. Because copyright law as codified in the 1976 Act requires human authorship, the Work cannot be registered.
In other words, as far as the US Copyright Office is concerned, output from programs like ChatGPT or Stable Diffusion are not eligible for copyright protection. Now, that could change if Congress gets involved (are they actually capable of doing anything?), or if the Supreme Court turned its collective back on decades of precedent (which, admittedly, has been happening recently). But unless something rather dramatic happens along these lines, the outputs of generative AI programs will continue to pass immediately into the public domain. Consequently, they will be open educational resources under the common definition:
Open educational resources (OER) are teaching, learning, and research materials that are either (1) in the public domain or (2) licensed in a manner that provides everyone with free and perpetual permission to engage in the 5R activities.
Generative AI tools could have an incredible impact on the breadth and diversity of OER that exist, since they will dramatically decrease the cost and time necessary to create the informational resources that underlie these learning materials. Current funding for the creation of OER (when it’s available at all) typically focuses on the courses enrolling the largest number of students. This makes sense when your theory of philanthropy is that the money you spend should benefit the most people possible. But that theory of philanthropy also means that the “long tail” of courses that each enroll relatively few students are unlikely to ever receive funding. LLMs will radically alter the economics of creating OER, and should make it possible for OER to come to these courses as well. (And while LLMs will have a significant impact on the economics of creating OER, they may not have as dramatic an impact on the sustainability, maintenance, and upkeep of OER over time.)
Two potentially interesting questions: First, in the same way teachers are worried about students submitting work written by LLMs, the same issue is coming for the US Copyright Office. If the output of these tools are not eligible for protection, the Office will soon have a deep interest in understanding which works are created by machines and which are truly the result of human creativity.
Second, how much time and effort would need to be invested in improving the drafts created by one of these tools before the improved version would be recognized as a derivative work that is eligible for copyright protection? (Think about Pride and Prejudice and Zombies. While it was based on a public domain work, it was transformed sufficiently to deserve its own copyright protection.)
The Impact on Traditional Publishers and OER
I’ve written before that OER advocates would eventually be sorry that they based their advocacy almost exclusively on cost savings, because the price of proprietary learning materials will come down and that talking point will evaporate:
[While] the cost of traditionally copyrighted educational materials has historically been much higher than the price of OER, the cost of textbooks has plateaued for the first time in decades (Perry 2020). As publishers respond to the price pressure created by OER in the course materials market, the difference in the prices of OER and traditionally copyrighted resources is likely to continue to decrease. If the access hypothesis holds, the impact of OER on student outcomes attributable to affordability will decrease in parallel. In other words, adopting OER may not be a long-term strategy for saving students significant amounts of money or closing the achievement gap between lower income and higher income students. (2021)
The impact of LLMs on the economics of creating proprietary materials should be the same as it is for OER (assuming publisher adapt to this new reality). As “big name authors” become supplanted by “big name editors” of work initially drafted by LLMs, the amount of royalties publishers owe to authors will either decrease significantly or may even disappear altogether. Now able to produce and sell proprietary material much less expensively than they were in the past, publishers could either pass this savings on to students in order to compete even more effectively with the price of OER, or simply use the savings to improve their margins, or a little of both. The key point here is that the boon of LLMs for learning materials production is NOT exclusive to OER. In fact, the benefit may accrue disproportionately to publishers of proprietary materials since the publishers of OER have never had to pay royalties. LLMs may put proprietary materials on equal footing with OER in this regard.
The Age of the Instructional Designer
We’ve been saying for more than a decade that content is a commodity. That is more true in the context of LLMs than it ever has been before. If content doesn’t differentiate learning materials from one another, what will? It’s possible we may finally be reaching a time when effectiveness will come to the forefront as the primary difference between learning materials. And while content accuracy is the domain of SMEs, effectiveness at supporting learning is the domain of instructional designers.
As the role of SMEs changes from author to editor and their time commitment to projects decreases, the role of instructional designers will grow in importance and effort. The instructional designer is likely the primary prompt engineer. Instructional design expertise will be reflected in the output of these systems in proportion to the degree that instructional design expertise is embedded in the prompts fed into the systems. IDs will engineer prompts and feed them into systems and then do rounds of rapid review of outputs with SMEs at each step in the process from the beginning (what is missing from this list of learning outcomes?) to the end (does the feedback on this formative assessment item accurately correct the misunderstanding a student likely has when they select option B?). As accuracy is being assured via this process, a significant amount of instructional design expertise will need to be applied to the varied outputs of these systems to bring them together in a cohesive, coherent way that will effectively support learning. Again, the right way to think about these tools is that they are incredibly helpful for creating first drafts for humans to then review, augment, and polish. And, when it comes to creating learning materials that are highly effective for all learners, there will be plenty of augmenting and polishing to do.
What an incredible time to be an instructional designer! Every school that teaches instructional design needs to immediately update their curriculum to leverage the existence of these tools. Using LLMs and other AI effectively (e.g., creating custom images) will be a key part of preparing instructional designers for the next decade – a decade that looks to be an absolutely incredible time to be an instructional designer!
You must be logged in to post a comment.